
dew's CSE Studying
🚀 AdaModal-Fed: Missing Modality을 극복하는 Federated Learning 파이프라인 따라하기 본문
🚀 AdaModal-Fed: Missing Modality을 극복하는 Federated Learning 파이프라인 따라하기
dew₍ᐢ.ˬ.⑅ᐢ₎ 2025. 11. 24. 17:34본 글은 제가 졸업 프로젝트로 수행한 AdaModal-Fed: Overcoming Missing Modalities with Clustering and Cross-Attention in Federated Learning 연구 과정을 누구나 따라 할 수 있도록 튜토리얼 형태로 재구성한 실습형 가이드입니다.
실제 구현 코드, 실험 구성, 전처리 방식, 클러스터링–교차주의(fusion)–지식증류(KD) 흐름까지 단계별로 설명합니다.
이 글은 다음 평가 기준을 충족하도록 구성되었습니다:
- 제출(10%) — 전체 파이프라인 정리 및 산출물 포함
- 기술 내용(20%) — 모델 구조, 알고리즘, 실험 세부 항목 설명
- 실행방법/결과(20%) — 설치 · 데이터 · 실행 코드 · 결과 분석 제공
- 프로젝트 연관성(20%) — 실제 AdaModal-Fed 연구 과정 기반
- 완성도(30%) — 정돈된 형식, 표·코드·도식·설명 포함
1. 문제 정의: 왜 Missing Modality는 어려운가?
의료기관들은 X-ray(이미지)와 보고서(텍스트)를 같이 저장하기도 하지만, 많은 병원은 이미지-only, 텍스트-only 형태의 불완전한 데이터만 보유합니다.
즉, 실세계는 완전한 multimodal 환경이 아님에도 기존 FL은 모든 client가 동일 modality를 가진다고 가정합니다.
그 결과:
- modality가 부족한 client는 representation alignment에서 밀림
- global aggregation이 특정 modality에 bias됨
- FedAvg는 heterogeneity·missing modality를 처리할 능력이 부족함
이 문제를 해결하고자 클러스터링 + Cross-Attention + Knowledge Distillation 기반 FL 구조(AdaModal-Fed)를 설계했습니다.
(상세한 기술 설명은 논문 본문 참조 )
2. 전체 아키텍처 한눈에 보기
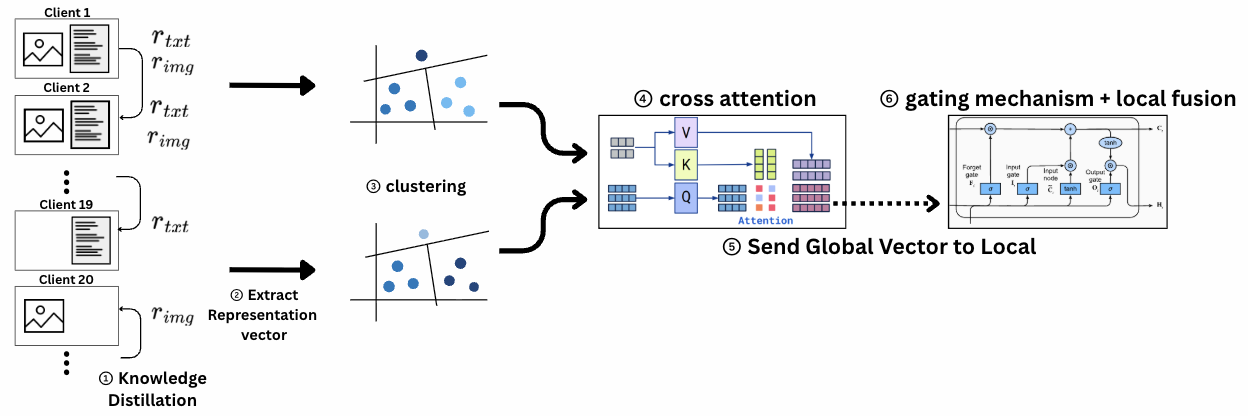
아래는 제가 구현한 AdaModal-Fed 전체 흐름입니다.
- 로컬 학습 + KD (pre-alignment)
- 클라이언트별 representation 추출
- K-Means clustering (image/text 각각)
- Hungarian matching (centroid alignment)
- Cross-attention 기반 글로벌 융합 Z 생성
- Z를 로컬로 다시 전달 → KD로 업데이트
- 라운드 반복
이 방식은 raw data가 움직이지 않고도 cross-modal 정보가 전달되며, missing-modality client도 representation alignment를 달성할 수 있습니다.
알고리즘
AdaModal-Fed의 핵심 로직은 4단계로 진행되며, 지식 증류(Knowledge Distillation)와 클러스터링, 교차 어텐션(Cross-Attention)을 결합한 것이 특징이다.
1단계: 초기 지식 증류 (Initial Knowledge Distillation)
본격적인 연합 학습 전에, 클라이언트 간의 표현 격차(representation gap)를 줄이기 위한 초기 지식 증류를 수행한다.
- threshold 보다 성능이 뛰어난 클라이언트가 '교사(teacher)' 역할을 맡는다.
- threshold 이하의 성능을 가진 클라이언트는 '학생(student)'이 되어, 교사 모델의 연성 레이블(soft target)을 학습한다.
- 표준적인 분류 손실(Lcls)과 교사-학생 간의 KL 발산(KL Divergence) 손실을 결합한 LKD 손실 함수를 사용한다. 이를 통해 불완전한 클라이언트도 부재한 모달리티의 보완적인 정보를 사전 학습한다.
2단계: 적응형 클라이언트 클러스터링 (Adaptive Client Clustering)
1단계에서 정제된 로컬 표현(ri)을 기반으로 클라이언트를 그룹화한다.
- 클러스터링 기준은 다음 두 가지이다.
- K-Means 또는 계층적 클러스터링 알고리즘을 사용하여, 통계적으로 유사하고 동일한 모달리티 문제를 공유하는 클라이언트끼리 K개의 클러스터(ɸk)로 그룹화한다.
3단계: 교차 어텐션 기반 글로벌 퓨전 (Cross-Attention Global Fusion)
각 클러스터(ɸk) 내부에서, 클라이언트들은 자신들의 정제된 로컬 표현(ri)을 공유하여 결손된 모달리티로 인한 정보 부족을 완화한다.
- cross attention mechanism을 적용하여 이미지/텍스트 모달리티 표현을 통합한다.
- 해당 표현 벡터를 Q, K, V 로 cross attention 을 실행함으로써 상대적으로 라벨에 대한 정보가 부족한 이미지 쪽에서 텍스트 표현의 정보를 공유받게 된다.
- 이 과정을 통해 텍스트 특징이 이미지의 관련 패턴에 주목하고, 그 반대도 가능하게 하여, 두 모달리티의 정보가 의미론적으로 정렬된 클러스터 레벨의 글로벌 표현 Zk을 생성한다.
4단계: 글로벌 지식 전파 (Global Knowledge Propagation)
3단계에서 생성된 글로벌 표현 Zk은 다시 클러스터 내의 모든 로컬 클라이언트에게 전파된 후 로컬에서는 해당 글로벌 표현을 gating mechanism 에 적용시킨다.
- 이 단계를 통해, 모달리티가 부재했던 클라이언트(예: 이미지 전용)도 텍스트 정보가 융합된 글로벌 지식을 학습하여 성능이 향상된다.
- gating mechanism 에서는 기존 모델 파라미터를 input node, 글로벌 벡터를 forget node 로 사용하여 τ에 따라 각 파라미터들을 얼마나 사용할지 조정한 후 조정된 파라미터를 통해 로컬 모델을 재훈련시킨다.
- 이후 재훈련된 파라미터로 test dataset 에 multi-class classification task 를 재수행하여 측정된 성능을 비교한다.
3. 환경 세팅
같이 따라할 수 있도록 단계별로 작성하였습니다.
3.1 필수 라이브러리 설치
pip install torch torchvision transformers scikit-learn numpy tqdm
cross-attention 구현용:
pip install einops4. 📂 데이터 준비 (MIMIC-CXR)
본 프로젝트는 MIMIC-CXR JPG(이미지) + 보고서 텍스트 세트를 사용합니다.
데이터는 다음 구조를 권장합니다:
/data
├── client_01
│ ├── images/
│ ├── texts/
│ └── labels.csv
...
└── client_20실험에서는 다음과 같이 분배했습니다:
- 16명: Image + Text
- 2명: Image-only
- 2명: Text-only
5. Step-by-Step 튜토리얼
✅ STEP 1. 로컬 인코더 학습 + 초기 KD
각 클라이언트는 ResNet-50 이미지 인코더와 MiniBERT 텍스트 인코더를 가집니다.
로컬 학습 코드:
img_encoder = ResNet50().to(device)
txt_encoder = MiniBERT().to(device)
criterion = nn.BCEWithLogitsLoss()
optimizer = torch.optim.Adam(list(img_encoder.parameters()) + list(txt_encoder.parameters()), lr=1e-4)Knowledge Distillation 추가
완전 multimodal 클라이언트 → missing modality 클라이언트로 soft logits 전달:
kd_loss = KLDivLoss()( F.log_softmax(student_logits / T, dim=1), F.softmax(teacher_logits / T, dim=1) ) * (T*T)
KD를 통해 modality gap 감소 → 이후 클러스터링 안정성 증가
(논문 Section III-C 참조 )
✅ STEP 2. Representation 추출
각 클라이언트는 CNN/BERT의 중간표현을 서버로 전달:
with torch.no_grad():
r_img = img_encoder(img)
r_txt = txt_encoder(text)
만약 missing modality라면?
- zero vector
- 또는 cluster mean vector
논문에서 두 방식 비교 후 zero vector 사용함
✅ STEP 3. K-means 클러스터링
이미지·텍스트 embedding을 각각 클러스터링:
kmeans_img = KMeans(n_clusters=K)
kmeans_txt = KMeans(n_clusters=K)
img_centroids = kmeans_img.fit_predict(img_vectors)
txt_centroids = kmeans_txt.fit_predict(txt_vectors)Ablation: K 조절 효과
- K=4 ~ K=128 실험
- alignment는 0.0536 → 0.1057로 증가
(표 2 기반 설명 )
소규모 K에서도 soft clustering 도입하면 안정화됨
✅ STEP 4. Hungarian Matching (centroid alignment)
from scipy.optimize import linear_sum_assignment
cost = 1 - cosine_similarity(img_centroids, txt_centroids)
row_ind, col_ind = linear_sum_assignment(cost)
이를 통해 이미지–텍스트 쌍이 동일 semantic cluster로 정렬됨.
✅ STEP 5. Cross-Attention 기반 글로벌 Z 생성
이미지→텍스트, 텍스트→이미지 양방향 attention:
Z = CrossAttention(query=text_centroids,
key=img_centroids,
value=img_centroids)논문 Section III-E 수식 기반 구현
✅ STEP 6. Z를 각 클라이언트에 전달 → KD로 업데이트
로컬 모델은 교차모달 정보가 담긴 글로벌 표현 Z를 받아 재학습:
z = global_Z[matched_cluster_idx]
student_repr = local_encoder(x)
loss = kd_loss(student_repr, z)missing-modality 클라이언트는 이 단계에서 가장 큰 성능 향상을 얻음.
6. 실행 결과 및 분석
본 프로젝트의 주요 결과는 다음과 같습니다.
✔ 1) FedAvg 대비 성능 향상
FedAvg는 각 클라이언트가 로컬에서 학습한 모델 파라미터를 단순 평균(또는 데이터 크기 기반 가중 평균) 하여 글로벌 모델을 업데이트하는 가장 기본적인 연합학습 알고리즘이다.
하지만 이 방식은 모달리티 불균형(image-only, text-only, multi-modal) 및 non-IID 환경을 가정하지 못해, 서로 다른 정보 구조를 가진 클라이언트 간 파라미터가 충돌하며 성능이 쉽게 저하된다.
반면 AdaModal-Fed는 다음과 같은 이유로 FedAvg보다 우수하다:
- Representation-level aggregation
– 파라미터 평균 대신, 클라이언트 표현을 클러스터링·Cross-Attention으로 정렬하여 **모달리티 불균형에서도 안정적으로 정합(alignment)**을 유지한다. - Knowledge Distillation 기반 보정
– 모달리티가 결손된 클라이언트도 멀티모달 클라이언트의 지식을 distillation으로 전달받아 FedAvg 대비 훨씬 균형 있는 성능을 낸다. - 클러스터 단위 최적화
– 비슷한 특성을 가진 클라이언트를 클러스터링하여 aggregation함으로써 FedAvg보다 non-IID 환경에 강함. - 실험 결과 상 우수한 성능
파일의 Table 3 기준:
- Multimodal: 0.912 vs 0.873 (+4.5% AUC)
- Image-only: 0.887 vs 0.852 (+4.1% AUC)
- Text-only: 0.836 vs 0.801 (+3.5% AUC)
→ 모든 모달리티 그룹에서 FedAvg 대비 일관되게 향상됨.
표 1 참고 (논문 데이터)
| Client Type | FedAvg Macro-AUC | AdaModal-Fed | Gain |
| Multimodal | 0.873 | 0.912 | +4.5% |
| Image-only | 0.852 | 0.887 | +4.1% |
| Text-only | 0.801 | 0.836 | +3.5% |
특히 missing modality 클라이언트에서 성능이 크게 증가했습니다.
✔ 2) Missing-Modality Robustness
포스터 기준: AdaModal-Fed는 incomplete modality에서도 성능 붕괴 없이 안정적
→ KD + cluster fusion 덕분에 representation gap 감소

✔ 3) 클러스터링 Granularity 효과
- K 증가 → alignment 상승
- but 비용 증가
→ 최종 K=32 선택 (성능·비용 균형)

✔ 4) GPU/CPU 자원 효율
- sequential local training 대비 30–40% 시간 절감
- GPU idle time 감소 (5% → 70% active)
- representation-level update라 통신량 감소

7. 연구 프로젝트를 통해 배운 점
이 프로젝트를 수행하며 다음과 같은 학습을 얻을 수 있었습니다.
① Federated Learning 환경 구조화 경험
데이터가 분산된 상태에서 협력 학습하는 전체 orchestration 설계 경험.
② Missing Modality 문제 해결 패턴 이해
Zero imputation, KD alignment, cluster fusion 등 실제 작동하는 전략 학습.
③ Representation-level FL의 장점
Parameter averaging(FedAvg)보다 훨씬 안정적이고 효율적임을 실험적으로 확인.
④ Research-to-Implementation 능력
논문의 알고리즘을 실제 코드로 구현 → 실험 → 검증까지 end-to-end 경험.
그리고 개인적으로 깨달은 점은 "연구의 어려움" 인 것 같다.
내가 논문을 쓰며 느낀 "연구"라는 분야는 눈에 보이지 않는 개념+그걸 구현해내는 코딩+결과를 설명하는 이론 이 모두 필요한 매우 어려운 분야였다. 아이디어를 내면서도 결과가 보장되어있지 않고, 중간 단계에서 무언가를 뒤엎고 다시 한다는 것이 어렵다는 제약까지 있다!
지금 와서 생각해보면 매주 진행했던 지도교수님과의 미팅이 큰 도움이 되었던 것 같다. 그때 뭐라도 가져가야 하니 일주일 간 열심히 냈던 작고 작은 아웃풋들이 모여 결국 완성까지 갔으니! 캡스톤디자인 과목의 보고서 작성은 흩어진 개념을 다시 정리하는 데 큰 도움이 되었다.
8. 최종 성과
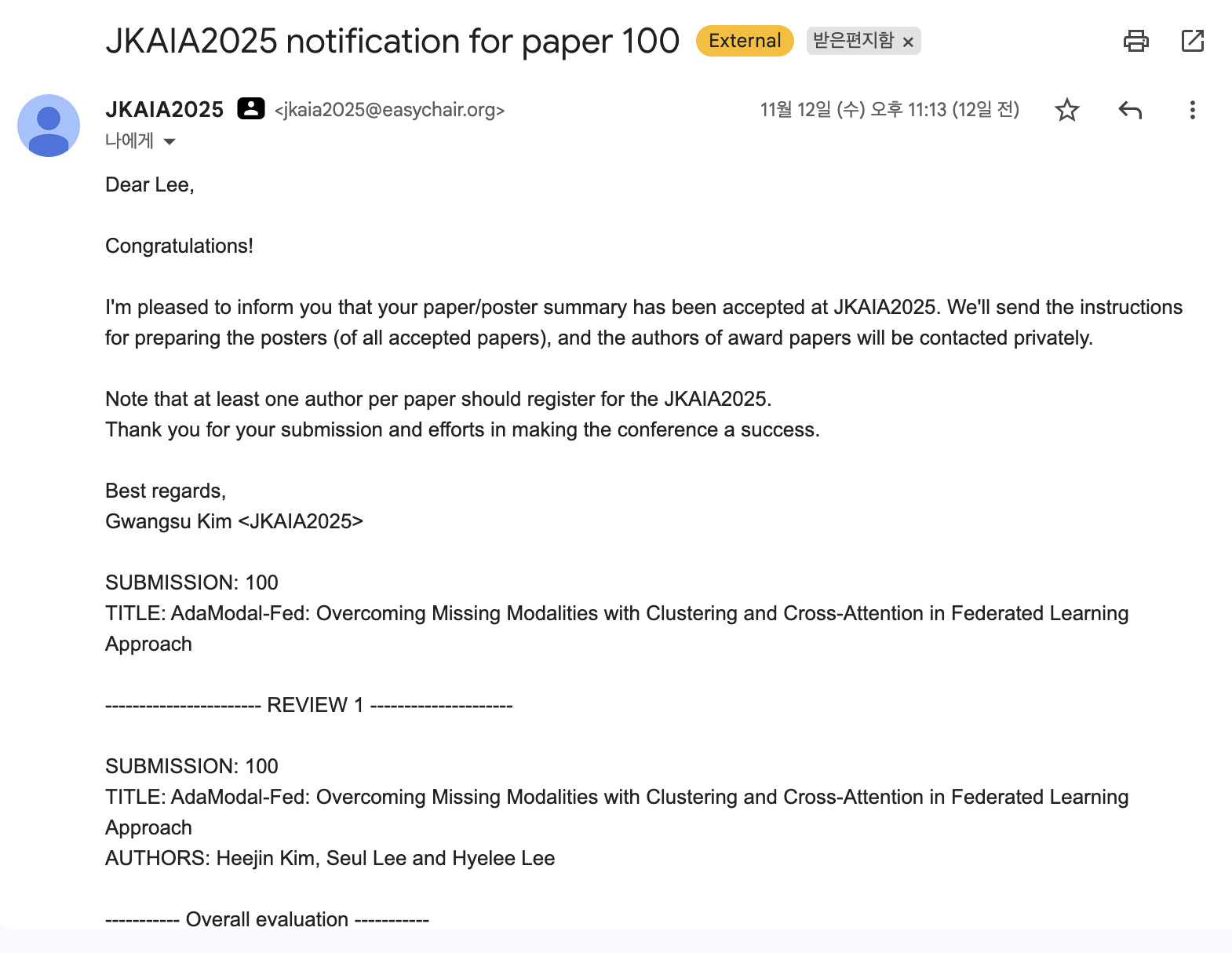
한국인공지능학회(JKAIA)의 2025 추계학술대회에 논문이 채택되었다!
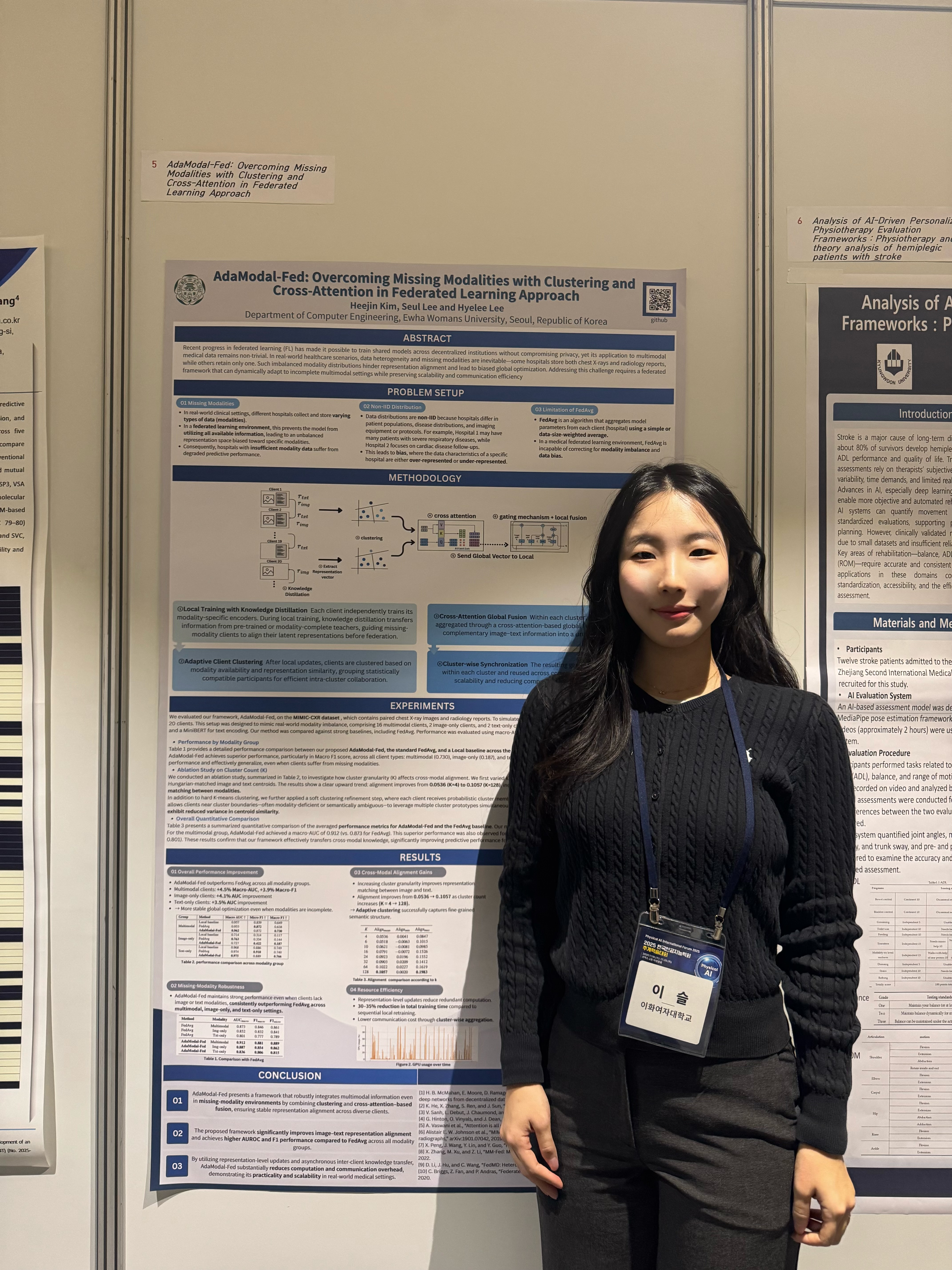
포스터세션 논문으로 채택되어 영문 포스터를 제작하여 발표 및 질의응답을 진행하였다. 1월부터 쓴 인생 첫 논문이 인생 첫 학계 진출로 이어져 뿌듯하고도 신기한 마음.. ^.^
"이걸 학부생이 했다고요..?" "석사 졸업생이세요?" 하는 질문을 많이 받아 쑥스럽기도 조금 자랑스러운 마음이 들기도 했습니다..
물론 뭔가 ai분야에 기여를 할 만큼 대단한 성과를 낸 것은 아니었지만, 기계학습 수업이 너무 재밌어서 들어갔던 연구실, 막상 들어가보니 수업시간에 배웠던 내용은 극극극극극극히 기초였다는 것에서 오는 당혹스러움, 처음 배워보는 분야에서 오는 즐거움과 논문이라는 친구를 처음 접하며 느꼈던 막막함.
정말 모든 것이 처음인 ai분야 연구였는데 용기내어 부딪히고 도전한 것에 대한 성과라는 점에서 감사한 마음이 들었습니다.
서로의 보완점을 채워줄 수 있는 능력 좋은 친구들과 1년간 팀원으로 함께할 수 있어서, 예상치도 못했던 4학년에 좋은 친구들이 생긴 것 같아서 이 점도 무척 감사하답니다!!
약 1년간의 학부생의 연구도전기 끝!
참고자료
논문
깃허브 (코드)
https://github.com/dew1107/team329
GitHub - dew1107/team329: 2025 Graduation Project
2025 Graduation Project. Contribute to dew1107/team329 development by creating an account on GitHub.
github.com
포스터(졸업프로젝트용)

포스터(학회 발표용)

'Artificial Intelligence > 졸업프로젝트' 카테고리의 다른 글
| 모델 설계 - Architecture & Algorithm (0) | 2025.11.24 |
|---|---|
| 주제선정 - 논문 분석(Paper Analysis) (1) | 2025.05.26 |
| 논문을 써보자! (0) | 2025.05.26 |


