
dew's CSE Studying
모델 설계 - Architecture & Algorithm 본문

3.2. 전체 시스템구현
a) 전체 개요
본 연구에서 제안하는 시스템은 연합학습(Federated Learning) 기반의 의료 데이터 분석 플랫폼으로, 클라이언트 단에서의 멀티모달 데이터 처리와 중앙 서버의 글로벌 모델 업데이트 과정을 통해 missing modality 문제를 해결한다.
b) 주요 구성 요소
- 클라이언트(Client)
- 클러스터링 모듈(Clustering Module)
- Knowledge Distillation 모듈
- Cross-Attention 기반 표현 학습 모듈
- 연합학습 서버(Federated Server)
c) 데이터 및 학습 흐름
- 이미지-텍스트 모달리티가 동시에 존재하는 의료 데이터 - ROCO v2, MIMIC-CXR-jpg 사용(x-ray 사진-의사의 진단 pair)
- 각 클라이언트는 로컬 데이터(이미지/텍스트)를 사용하여 모델 학습 수행
- 로컬 모델 성능별로 그룹핑 후 그룹 내에서 Teacher–Student 기반 Representation-level KD 진행하여 로컬 단위의 성능 보완
- 로컬 모델에서 추출한 표현 벡터는 클러스터링 모듈에 의해 그룹화
- Cross-Attention 모듈을 통해 이미지/텍스트 통합 글로벌 표현 학습
- 로컬 모델 파라미터는 중앙 서버로 전송되고, 서버는 이를 집계하여 글로벌 모델 업데이트
- 업데이트된 글로벌 모델은 다시 각 클라이언트로 배포되어 반복 학습 수행
4. 주요 기능 구현
본 연구에서 제안하는 'AdaModal-Fed' 프레임워크는 이종(heterogeneous) 클라이언트 환경, 특히 일부 클라이언트가 특정 모달리티(modality) 데이터를 보유하지 않은 '모달리티 부재(missing modality)' 상황에 대응하기 위해 설계되었다. 전체 구현은 다음과 같은 핵심 단계로 구성된다.
4.1. 로컬 모델 구현
각 클라이언트는 자체 보유한 데이터를 학습하기 위한 모달리티별 인코더를 가진다.
- 이미지 인코더 (Image Encoder): ResNet-50 모델을 사용하여 시각적 특징(visual feature)을 추출
- 텍스트 인코더 (Text Encoder): MiniBERT 모델을 사용하여 텍스트 보고서로부터 언어적 특징(textual feature)을 추출
모달리티가 부재한 경우, 해당 인코더의 부재한 모달리티 임베딩은 무시되며, 모든 클라이언트가 일관된 차원의 잠재 공간에서 연산을 수행할 수 있도록 정규화된다.
4.2. 핵심 알고리즘 구현: 4단계 적응형 연합 학습
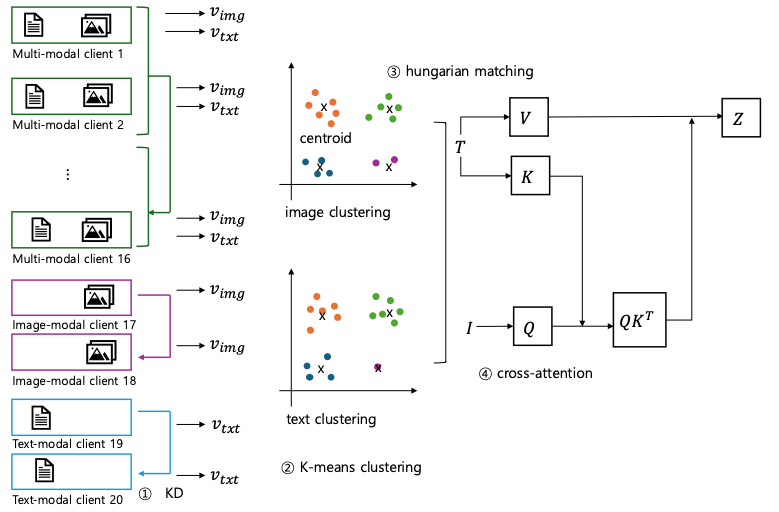
AdaModal-Fed의 핵심 로직은 4단계로 진행되며, 지식 증류(Knowledge Distillation)와 클러스터링, 교차 어텐션(Cross-Attention)을 결합한 것이 특징이다.
1단계: 초기 지식 증류 (Initial Knowledge Distillation)
본격적인 연합 학습 전에, 클라이언트 간의 표현 격차(representation gap)를 줄이기 위한 초기 지식 증류를 수행한다.
- threshold 보다 성능이 뛰어난 클라이언트가 '교사(teacher)' 역할을 맡는다.
- threshold 이하의 성능을 가진 클라이언트는 '학생(student)'이 되어, 교사 모델의 연성 레이블(soft target)을 학습한다.
- 표준적인 분류 손실(Lcls)과 교사-학생 간의 KL 발산(KL Divergence) 손실을 결합한 LKD 손실 함수를 사용한다. 이를 통해 불완전한 클라이언트도 부재한 모달리티의 보완적인 정보를 사전 학습한다.
2단계: 적응형 클라이언트 클러스터링 (Adaptive Client Clustering)
1단계에서 정제된 로컬 표현(ri)을 기반으로 클라이언트를 그룹화한다.
- 클러스터링 기준은 다음 두 가지이다.
- K-Means 또는 계층적 클러스터링 알고리즘을 사용하여, 통계적으로 유사하고 동일한 모달리티 문제를 공유하는 클라이언트끼리 K개의 클러스터(ɸk)로 그룹화한다.
3단계: 교차 어텐션 기반 글로벌 퓨전 (Cross-Attention Global Fusion)
각 클러스터(ɸk) 내부에서, 클라이언트들은 자신들의 정제된 로컬 표현(ri)을 공유하여 결손된 모달리티로 인한 정보 부족을 완화한다.
- cross attention mechanism을 적용하여 이미지/텍스트 모달리티 표현을 통합한다.
- 해당 표현 벡터를 Q, K, V 로 cross attention 을 실행함으로써 상대적으로 라벨에 대한 정보가 부족한 이미지 쪽에서 텍스트 표현의 정보를 공유받게 된다.
- 이 과정을 통해 텍스트 특징이 이미지의 관련 패턴에 주목하고, 그 반대도 가능하게 하여, 두 모달리티의 정보가 의미론적으로 정렬된 클러스터 레벨의 글로벌 표현 Zk을 생성한다.
4단계: 글로벌 지식 전파 (Global Knowledge Propagation)
3단계에서 생성된 글로벌 표현 Zk은 다시 클러스터 내의 모든 로컬 클라이언트에게 전파된 후 로컬에서는 해당 글로벌 표현을 gating mechanism 에 적용시킨다.
- 이 단계를 통해, 모달리티가 부재했던 클라이언트(예: 이미지 전용)도 텍스트 정보가 융합된 글로벌 지식을 학습하여 성능이 향상된다.
- gating mechanism 에서는 기존 모델 파라미터를 input node, 글로벌 벡터를 forget node 로 사용하여 τ에 따라 각 파라미터들을 얼마나 사용할지 조정한 후 조정된 파라미터를 통해 로컬 모델을 재훈련시킨다.
- 이후 재훈련된 파라미터로 test dataset 에 multi-class classification task 를 재수행하여 측정된 성능을 비교한다.
'Artificial Intelligence > 졸업프로젝트' 카테고리의 다른 글
| 🚀 AdaModal-Fed: Missing Modality을 극복하는 Federated Learning 파이프라인 따라하기 (0) | 2025.11.24 |
|---|---|
| 주제선정 - 논문 분석(Paper Analysis) (1) | 2025.05.26 |
| 논문을 써보자! (0) | 2025.05.26 |


