

dew's CSE Studying
The Power of Scale for Parameter-Efficient Prompt Tuning 본문
The Power of Scale for Parameter-Efficient Prompt Tuning
dew₍ᐢ.ˬ.⑅ᐢ₎ 2025. 1. 7. 01:52Abstract
explore "prompt tuning," a simple yet effective mechanism for learning "soft prompts" to condition frozen language models to perform speific downstream tasks
prompt tuning
:모델에 입력되는 프롬프트(명령이나 요청등의 text)를 조정하여 모델이 원하는 방식으로 응답하도록 하는 것
chat gpt에 내가 입력하는 명령을 조정하여 모델의 성능을 높이는 것이다.
- model parameter의 수정 필요X
soft prompts
:자연어가 아닌 학습가능한 연속적인 벡터(continuous한 입력값을 말하는 것 같은데 이정도 개념으로 알아두자!)
- continuous&tunable
- 실수/벡터로 이루어진 연속값
- 자연어가 아님(↔discrete prompts: 자연어로 이루어짐←이건 GPT-3에서 사용)
- back propagation으로 학습됨
- 여러 개의 labeled example로부터 signal을 포함하도록 tune될 수 있음
frozen language model
:이미 학습된 모델의 일부 레이어층을 동결시켜서 해당 layer의 가중치가 변경되지 않도록 동결시킴. 이후 후속레이어나 특정 레이어만 학습하도록 함
end-to end learning approach
:입력~출력까지 모든 과정을 한번에 학습(모두 하나의 모델에서 스스로 학습)
-GPR-3의 few-shot learning의 성능을 뛰어 넘음
Introduction
previous techniques
우리의 관심사인 prompt tuning을 소개하기에 앞서서 이전의 techniques를 살펴보자.
model tuning(=fine tuning)
- 미리 학습된 모델을 특정 작업이나 dataset에 맞게 재학습시키는 과정
- 원하는 task에 특화된 supervised dataset을 학습시킴
- adaptation 중에 모든 model parameter들이 tuning됨
- 한계) large dataset의 필요, poor generalization, 전체 LM의 파라미터 수정 필요, new text를 학습시키는 데 기존 모델의 전체 copy 필요(각 end task마다 이 copy를 저장해야한다ㅠㅠ)
- ex) ELMo(Embeddings from Language Model, 2018), GPT(2018), BERT(2019)
- 더보기
ELMo (2018)
-pre-trained model의 freezing 기법을 처음 제안
-task-specific weighting of its per-layer representations
prompt design(=priming)
- text prompt를 통해 frozen GPT-3의 모델 행동을 modulating하는데 효과적
- ex)GPT-3
prompt tuning(✨)
- 각 task마다 small task-specific prompt만 저장하면 된다
- 모델 크기가 클수록 good
- reuse freezing model(이 모델 하나를 여러 downstream tasks에 적용할 수 있게 된다)
- original model만 갖고 mixed-task 수행이 가능
prompt-based adaptation의 한계점⚠️
- error-prone: 에러가 발생하기 쉽다
- 인간의 개입이 필요: 프롬프트를 설계/조정에서 사람의 판단과 결정이 중요
- input에 fit할 수 있는 conditional text의 양에 따라 prompt 효과가 제한
conditional text: 모델이 특정 작업을 수행하거나, 특정 스타일로 응답을 생성할 수 있도록 도와주는 배경 정보나 맥락
=>downstream task의 성능 <<< tuned model의 성능
ex) GPT-3 175B few-shot performance on SuperGLUE의 성능 <<< fine-utned T5-XXL의 성능
심지어 GPT-3는 16배 더 많은 파라미터를 사용!
prompt design 자동화
'prompt를 사람이 수동으로 작성하지 않고 자동화된 시스템이나 알고리즘을 사용할 수는 없을까?'
Auto prompt by Shin et al.(2020)
- 검색 알고리즘 제안
- manual prompt design보다 성능 good
- model tuning에 비교해서는 still gap이 존재
Prefix Tuning by Li and Liang(2021)
- "prefix tuning"
- LM의 파라미터 freeze(기존 fine tuning에서는 전체 LM의 파라미터를 수정해야 했음)
- prefix라고 불리는 continuous task-specific vector을 최적화(encoder stack+input layer에 prepended 되어있음)
- prefix activation을 tuning하는 동안 error을 backpropagate한다
WARP by Hambardzumyas et al.(2021)
- prefix tuning을 simplify함: input&output subnetworks에 학습 가능한 파라미터를 제한시킴
- classification task에서 유의미한 결과 제공
Prompt Tuning(new✨)
- 전체 pre-trained model을 freeze
- input text에 prepend되는 걸 각 task마다 오직 additional k tunable token으로 제한(뭔말인진 모르겠지만ㅠㅠ일단 그렇다고 하자)

얘를 보면 좀 이해가 되는 게 prompt tuning을 보면 기존 input text 앞에 추가적으로 tunable(학습 가능한) soft prompt(continuous한 vector)가 붙어있다.
- 이 soft prompt의 train 방식: end-to-end: 입력에서 출력까지 파이프라인 네트워크 없이 신경망으로 한 번에 처리
- 전체 라벨이 지정된 데이터셋에서 중요한 정보를 추출가능→few-shot prompts의 성능을 뛰어 넘게 해줌+model tuning과의 quality gap을 줄이게 해줌
- frozen model의 효율적인 serving benefit을 유지: pretrained model이 여러 tasks에 걸쳐 recycle되니까!
key contributions🔑
- prompt tuning을 제안+model tuning에 대한 경쟁력 증명(특히 large language model에서)
- scale이 커질수록 quality와 robustness(견고성) 증가
- domain shift problem에서 prompt tuning이 model tuning을 뛰어넘는 것 증명
- prompt ensembling 제안+effictiveness 증명
Prompt Tuning
Text generation
T5에서 이거 사용!
$\mathbf{Pr_\theta (Y|X) }$
Y:sequence of tokens that represent a class label
X:series of tokens
θ:transformers that make up its encoder&decoder
Prompting
:Y의 generation 과정에서 extra information을 조건으로 하기 위해 추가하는 것
-즉, input X에 series of tokens P를 붙이는 과정이 prompting이다
- 모델이 주어진 입력 X에 대해 정답 Y를 예측할 확률을 최대화
- θ는 고정한 채로!!
-optimal prompt를 찾는 과정은 promp token을 선택하는 과정을 포함한다
(방법: manual search(사람이 수동 선택) / non-differentiable search methods(미분x))
Prompt Tuning
-prompt P가 θ에 의해 파라미터화 되는 제한을 없애준다
-대신 각각의 prompt는 update될 수 있는 own dedicated parameters θp를 갖는다
-prompt design: frozen embeddings의 fixed vacabulary에서 prompt tokens를 selecting하는 것
prompt tuning: special tokens의 fixed prompt를 사용하는 것(이 prompt tokens에 embeddings만이 update될 수 있다)
-new conditional genaration $Pr_{\theta ;\theta _ P}(Y|[P;X])$
-θ_P를 gradient하는 동안에만 Y의 likelihood를 backpropagation으로 maximize함으로써 train할 수 있다
Prompt Tuning 과정
- embed thd tokens
series of n tokens $\left\{ x_1, x_2,...,x_n\right\}$ - prompt는 embedded input에 concatenated된다
- 얘는 encoder-decoder을 통과한다
maximize the probability of Y
but only the prompt parameters Pe(=soft-prompts) are updated
2.1 Design Decisions
프롬프트의 표현을 초기화하는 방법
(prompt→모델의 input으로 사용할 수 있는 초기 벡터)
- 방법1: random initialization을 이용하여 처음부터 train시키기(가장 간단)
랜덤 초기화: 처음에는 프롬프트 표현을 무작위 값으로 초기화. 이후 학습을 통해 최적의 값을 찾아낸다. - 방법2: 사전학습된 임베딩 사용- 각각의 prompt token을 모델의 voabulary에서 추출된 embedding으로 초기화
(예: Word2Vec, GloVe 등)
개념적으로 soft-prompt에 의해 frozen network가 최적화되는 방식은 input 앞에 text가 선행하는 방식과 유사하다. soft-prompt의 초기 값으로 단어 수준의 embedding(vector representation)을 사용하는 것이 좋은 시작점이 될 수 있다.
- 방법3: (for classification tasks) 출력클래스를 나열하는 embeddings로 prompt를 initialize
"verbalizers"(2021): label 단어와 실제 클래스를 이어주는 매핑 함수
우리가 원하는 것=모델이 딱 특정 output에 있는 것만 tokenize하길 바람. 그래서 prompt를 해당 클래스에 대응하는 임베딩 벡터로 초기화하는 것이 중요하다! prompt에 의해 legal output class만이 출력값이 될 수 있도록 제한을 가하는 것이다. 이렇게 원하는 방향으로 모델을 유도하는 것을 prime이라고 한다.
Prompt의 길이
prompt의 길이 또한 고려해야한다.
parameter cost = EP 라고 할 때, E=token embedding dimension, P=prompt length이다.
즉, promp의 길이가 짧을수록 tune되어야 하는 새 파라미터의 수가 줄어든다! 그래서 prompt의 길이는 짧을 수록 좋다.
2.2 Unlerning Span Corruption
T5의 학습 방법
- encoder-decoder architecture
encoder:입력을 한 번에 처리 / decoder: 출력을한 번에 처리 =>병렬화로 속도↑ - pre-train on a span corruption objective
:pre-train 과정에서 문장에서 특정 부분(span)을 가려놓고, 이를 복원하는 방식으로 결손 정보를 예측하는 것
조금 더 자세하게 살펴보자!

이 예시로 이해해보자. 최종 goal은 maked span(치환된 부분)을 "reconstructing"하는 것이다.
input에서 랜덤으로 masking을 진행하고, targets에서는 이 sentinel token에 추가로 final sentinel이 추가되어있는 형태를 보인다. 2020년에 이 구조가 traditional language modeling보다 낫다고 밝혀지긴 했으나 우리는 이게 최선이 아니라고 가정한다.
가정: 이 설정이 prompt tuning을 통해 손쉽게 제어될 수 있는 frozen model을 생성하는데는 적합하지 않다
span corruption만을 사용하여 pre-trained된 T5 모델(ex.T5 1.1)은 자연스러운 입력 텍스트와 자연스러운 타겟 텍스트에 대한 예측을 둘다 관하지 못했다.
=>이 경우 단순 가려진 부분에 대한 예측만 진행되고, 문맥과 구어/문어의 자연스러움은 고려하지 않은 학습이었다.
이거는 fine-tuning으로 쉽게 해결할 수 있을 것 같긴 하지만 decoder의 우선순위가 조정될 수 없기 때문에 prompt만으로 해결하기는 어렵다.(T5에서는 decoder이 입력 text와 타겟 text사이의 관계를 다룬다)
실험 설정
- "Span Corruption": T5 모델을 사전 훈련된 상태 그대로 사용
goal: 모델이 기존 훈련 데이터에서 학습한 내용대로 기대하는 출력을 생성할 수 있는지 테스트 - "Span Corruption+Sentinel": 목표 텍스트에 'sentinel' 토큰을 추가하여 더 자연스럽게 사전 훈련 과정과 유사하게 만드는 방식
goal: 사전 훈련과의 유사성을 더 많이 반영하여 모델이 더 정확하게 출력을 예측할 수 있게 - "LM adaptation": T5 모델의 self-supervised 학습+"LM" objective 사용하여 추가학습(언어 모델 목표로, 모델이 단어 예측을 통해 텍스트를 생성하도록 학습)
input: a natural text prefix / output: the natural text continuation을 예측하여 생성하도록
*딱 한 번의 adaptation: 한 번 학습시킨 걸로 reuse~
goal: 빠르게 T5를 GPT-3와 유사하게 만듦(항상 realistic text를 output으로, "few-shot learner"로 prompts에 잘 반응)
Results
실험조건
- all size T5 checkpoint 위에 만들어진 frozen models(Small, Base, Large, XL, XXL)
- T5 1.1(T5보다 improve됨)
(1)pre-training에서 모든 supervised data 제거
(2) hyperparameters 과 에 대한 조정
(3)ReLU 말고 GeGLU 사용 - default config: LM-adapted version of T5 trained for additional 100K steps, class label 사용 initialize, prompt length: 100 token
->Li and Liang의 10-token prefix보다는 길지만 task-specific parameter은 더 적게 사용했음(얘는 input layer만 tune하면 되기 때문) - SuperGLUE benchmark
-translate all into a text-to-text formal
-단 task name 생략
-no multi-task setup, no mixing of training data across tasks - 30,000 steps prompts training(T5's standard cross-entropy loss 사용, learning rate 0.3, batch size 32)
- run in JAX
- using Adafactor optimizer(weight decay 1e-5, B2 decay 0.8, parameter scaling off)
3.1 Closing the Gap
standard model tuning과 비교해보자.
baseline
- "Model Tuning": 각 task를 개별 tuning(prompt tuning setup 때처럼)
- "Model Tuning(Multi-task)": single model이 모든 task에서 공동으로 tuning

prompt tuning이 XL와 XXL에서 prompt design을 큰 차이로 앞섰다
3.2 Ablation Study
Prompt Length
prompt length를 {1, 5, 20, 100, 150}으로 실험해보았다

- token이 하나보다는 많아야 좋은 성능
- XXL 모델과 같은 큰 모델의 경우, 단일 토큰 프롬프트만으로도 매우 강력한 성능을 발휘할 수 있다
=>크기가 큰 모델은 더 적은 conditioning signal이 필요 - 20 토큰을 넘어서는 프롬프트 길이는 성능 향상에 거의 미미한 차이
Prompt Initialization
다른 hyperparameter를 기본값으로 고정하면서 모든 크기의 모델을 훈련-> prompt initialization의 효과를 제거(ablate)

- random uniform: range [-0.5, 0.5]
- sampled vocabulary initialization: 5000 most common tokens로 제한, pre-training corpus에서 likelihood로 정렬
- class label initialization: 각 class의 string의 embeddings를 가져와 prompt의 하나의 토큰으로 초기화.
-if class-label이 multi-token이면 token embeddings를 average냄.
-if 프롬프트 길이가 길어지면, 클래스 레이블이 부족하여 남은 부분을 sampled vocab strategy로 돌아가서 prompt를 채움
[결과]
- class label initialization이 젤 성능 좋았다
- model size가 작을 때 initialization 방법들 사이에 gap이 컸다
- model size가 XXL가 되면 차이는 거의 사라졌다
- class label initialization 사용 시 learned 프롬프트에서 initialization에 사용된 클래스 레이블이 보존되는 경향
but learned propmpts가 해석 가능하진 않았음
Pre-training Objective
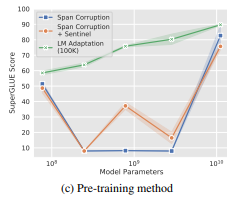
- span corruption은 frozen 모델을 나중에 프롬프트로 조건화하는 데 적합하지 않다 는 가설 검증.
이유: sentinel token과 함께 read/write한 애들은 sentinel token 없이 read/write이 어려움 - "workaround"방식(downstream target에 sentinel 추가): 성능 향상에 도움 X
- "LM adaptation": 모든 모델 크기에서 유의미한 성능 향상
-XXL model에서는 효과 미미, span corruption에서도 견고한 성능

- longer adaptation->additional gain
=>span corruption->laguage modeling objective로의 전환: 사소X, 상당한 training source투자가 필요 - XXL model은 non-ideal 상황에서도 견고함을 관찰
<non-optimal "span corruption" setting 에서>
- Small 모델은 기본 설정에서 다른 Base, Large, XL 모델들보다 더 나은 성능
(이유: span corruption을 사용할 경우 모델 크기에 따라 불안정성이 발생하기 때문) - mid-sized models: legal class label 예측 불가
가장 흔한 2가지 오류: 입력에서 sub-spans를 그대로 복사 / 빈 문자열을 예측
결론
- "Span corruption" 목표로 학습된 모델들은 성능 변동이 크고 신뢰할 수 없음
- "LM adaptation" 목표로 학습된 모델들이 모든 크기에서 일관되게 성능을 잘 유지
Comparison to Similar Approaches
continuous prompts 학습에 관한 최근의 연구들과 비교해보자. 이때 중요한 비교의 기준은 각 방법이 필요로 하는 task-specific parameter의 수이다.
prefix tuning
- prefix tuning: every transformer layer에 prepend된 prefixes를 학습 = every network layer에 고정된 transformer activations를 학습
- prompt tuning: embedded input에 prepend된 single prompt representation을 이용
| prefix tuning | prompt tuning |
| -더 많은 parameter 필요 | -requires fewer parameters |
| -transfer model이 intermediate layer에서 task representation을 업데이트할 수 있도록 함(input example이 contextualize되는 방식으로) | |
| -ex)GPT2, BART | -ex)T5 |
| -prefixes를 both encoder&decoder network에 포함 | -prompts는 encoder에만 필요 |
| -prefix의 reparameterization을 통해 학습의 안정성 확보(but 훈련 중 많은 추가 매개변수를 요구한다는 단점~) | -재매개변수화 필요X+다양한 SuperGLUE 태스크와 모델 크기에서도 강건성을 유지한다는 장점 |
WARP
- promp parameter들이 input layer에 더해진다
- Masked Language Models(예: BERT)에서 사용되며, [MASK] 토큰과 learnable output layer을 사용해 [MASK]를 class logits으로 투영.
- 한계: 모델이 단일 출력을 생성하도록 제한되므로, 주로 classification에만 적합
- prompt tuning: 입력 또는 태스크에 특정 헤드를 추가할 필요 없이 작동+strong 모델 튜닝 성능에 근접
P-tunning
- learnable continuous prompts를 입력 임베딩에 삽입(프롬프트 설계는 사람이 만든 패턴을 기반으로 함)
- 한계: complication, 강력한 성능(SuperGLUE)을 얻기 위해 모델 튜닝과 결합해야 함(모델이 prompt와 main model의 parameter을 둘다 업데이트 해야함)
- prompt tuning: prompt를 input에만 붙여서 복잡성 제거, original model은 frozen하게 만들어서 건들 필요 없음

soft words
- 학습 가능한 "soft words"를 사용해 prompts 생성→사전 학습된 언어 모델(pre-trained LM)에서 knowledge 추출
- 프롬프트는 사람이 설계한 프로토타입(prompt prototypes)을 기반으로 입력과 연관되어 배치
- 각 층(layer)에 대해 학습 가능한 $\bigtriangleup _{i}^{l} $ 매개변수를 포함
- 한계: 매개변수의 비용이 모델 깊이에 비례하여 증가
Learnable prepended token
- 학습 가능한 토큰을 input 앞에 추가하여 transformer 모델을 다양한 태스크에 adapt
- 한계: compositional task representation를 수용하기 위해 소규모의 synthetic datasets에 집중했는데, 이는 real-world dataset과는 차이가 있음
- base model은 처음부터 task representations와 합쳐져서 trained된다
- prompt tuning은 base model을 freeze하고 larger transformer을 이용하여 scaling law를 조사한다
adapters
- frozed pre-trained network layers 사이에 small bottleneck layers을 삽입
- task-specific parameters를 최소화하면서 성능을 유지
Houlsby et al. (2019): BERT-Large를 고정한 상태에서 2–4%의 추가 매개변수로 GLUE 벤치마크에서 전체 모델 튜닝과 유사한 성능을 달성함 - Pfeiffer et al. (2020): 다중언어(multilingual) 설정에서 여러 어댑터를 사용하여 language understanding / task specification 분리
- prompt tuning과의 차이: approach가 model behavior을 바꾸는 접근방식
| adapter | prompt tuning |
| -입력 표현을 다루는 함수 자체를 수정(any given layer에서 neural networks의 활성화값 재작성을 허용)하여 동작 변경 | -모델의 기본 함수는 수정하지 않고 input representation을 추가 |
Resilience to Domain Shift
prompt tuining의 이렇게 core language model을 freeze하는 방식은 모델이 general understanding of language를 수정하는 것을 막아주었다. 대신, prompt representations는 간접적으로 input의 representation을 조절하여 바꾼다. 이렇게 되면 model은 specific lexical cues와 거짓 상관관계를 memorize함으로써 overfit을 피한다.
=>prompt tuning이 training/evaluation에서의 input distribution이 다른 domain shift에서의 robustness를 증가시켜줄 수 있지 않을까??
Zero-shot domain transfer
두 가지 task
- Question answering(QA)
- paraphrase detection
QA
- MRQA 2019 shared task를 사용
-여러 추출형 QA 데이터셋(extractive QA datasets)을 unified format으로 제공
-모델이 "in-domain" 데이터셋(SQuAD)으로 학습된 후 "out-of-domain" 데이터셋(각각의 out-of-domain datasets)(TextbookQA, BioASQ, 등)에서 평가될 때 어떻게 수행되는지

=>prompt tuning이 대다수의 "out-of-domain" 데이터셋에서 모델 튜닝을 능가
- TextbookQA: 프롬프트 튜닝이 모델 튜닝보다 F1 점수에서 +12.5 포인트의 차이를 기록하며 가장 큰 성능 차이를 보임
- BioASQ: 프롬프트 튜닝이 도메인 이동(domain shift)이 큰 데이터셋(생물의학 분야)에 대해 성능 우위를 보임
- DROP: SQuAD와 동일 도메인(Wikipedia) 기반 데이터셋으로, 프롬프트 튜닝과 모델 튜닝의 성능 차이가 가장 적음
Paraphrase detection
- GLUE task
-QQP (Quora Question Pairs): Quora의 두 질문이 "중복"인지 판단
-MRPC (Microsoft Research Paraphrase Corpus): 뉴스 기사에서 두 문장이 패러프레이즈인지 판단 - 실험 세팅
-학습: QQP 또는 MRPC (in-domain)
-평가: MRPC 또는 QQP (out-of-domain, 제로샷 전이) - 결과
-QQP → MRPC: 프롬프트 튜닝이 모델 튜닝 대비 +3.2 accuracy, +3.1 F1의 성능 향상!
-MRPC → QQP: 두 접근법의 성능 차이가 거의 없음
=>model tuning은 over-parameterized, overfit 가능성
Prompt Ensembling
기존 ensembling
- 장점
-다양한 초기화에서 학습된 신경망 모델 앙상블은 태스크 성능을 향상시키고(Hansen & Salamon, 1990)
-모델의 불확실성 추정에도 유용함(Lakshminarayanan et al., 2017) - 한계
-저장 비용: 모델 크기가 커질수록 각 모델 복사본 저장 비용이 급증 (예: T5-XXL 모델 하나당 42 GiB)
-추론 비용: N개의 모델을 병렬 또는 순차적으로 실행하는 데 드는 비용이 큼
Ensembling with Prompt Tuning
- main idea
-여러 프롬프트를 동일한 태스크에 대해 학습시키면, 각 프롬프트가 하나의 독립적인 "모델"처럼 동작
-하지만 공유된 언어 모델 매개변수를 사용하므로 저장 공간과 추론 비용이 크게 줄어듦 - 효율성 개선
-저장공간: N개의 모델 대신 N개의 프롬프트만 저장 (언어 모델 자체는 단일 복사본만 유지)
-추론비용:하나의 예시를 N개의 모델로 각각 실행하는 대신, 배치 크기 N의 단일 forward pass로 추론 수행(배치 내에서 입력 예시는 복제되고, 프롬프트는 다양하게 적용됨) - 멀티태스킹과 유사한 이점: 저장 및 추론 비용 절감 효과는 멀티태스킹 상황(Figure 2)에서 관찰된 절감 효과와 유사
실험

- 설정
-SuperGLUE 태스크별로 5개의 프롬프트 학습
-프롬프트 앙상블은 단일 T5-XXL 모델과 기본 하이퍼파라미터를 사용
-예측은 Majority Voting으로 계산 - 결과
-프롬프트 앙상블의 성능은 단일 프롬프트의 평균 성능을 능가
-앙상블의 성능은 최고 성능을 보인 개별 프롬프트와 동일하거나 더 나음
Interpretability
ideally interpretable한 prompt는 자연어로 구성되어 task를 명확하게 설명하고, result action에 대해 model에 요청할 수 있으며 해당 행동에 대해 쉽게 이해시킬 수 있어야 한다. prompt tuning은 보통 descrete token space보다 continuous embedding space에서 동작하므로 interpreting 자체는 좀 더 어렵다. 그럼 interpretability는 어떻게 test할까? 우리는 frozen model의 vocabulary에서 추출한 각각의 prompt token의 nearest neighbors를 계산하기로 하자. 즉, vocabulary embedding vector와 prompt token representation 사이의 cosine distance를 사용하는 것이다.
관찰결과
:학습된 prompt token에 대해 가장 가까운 상위 5개의 이웃이 tight한 sematic cluster를 형성한다
ex)lexically similar clusters: {Technology/ technology/ Technologies/ technological/ technologies}
다양하지만 강한 연관: {entirely/ completely/ totally/ altogether/ 100%}
=>prompt들은 사실상 "word-like" 표현을 학습한다. embedding space에서 추출된 random vector들은 이러한 semantic clustering이 관찰되지 않는다.
prompt 초기화 관련
- "class-label"초기화: class labels가 training을 통해 지속된다. 초기화된 그 label이 tuning 후에도 학습된 토큰의 nearest neighbors로 나타난다
- Random Uniform / Sampled Vocab 초기화: 클래스 레이블이 여러 프롬프트 토큰의 이웃으로 나타나기도 한다. 그러나 multiple prompt token의 이웃으로 나타나는 경향이 있다
=>model이 prompts에서 expected output classes를 참조하여 저장한다. prompt를 output class들로 initialize하는 것은 이 작업을 더 쉽고 centralized되게 만들어준다.
prompt의 길이 관련
- 같은 이웃을 가진 prompt token들이 있다
=>프롬프트에 초과 용량이 있음, 프롬프트 표현에 순차적 구조가 부족하여 특정 위치에 정보를 집중시키기 어려움
학습된 prompts의 해석 가능성
학습된 프롬프트를 시퀀스 전체로 보면 해석 가능성이 낮지만, "science", "technology"와 같은 특정 단어가 높은 빈도로 나타남.
=>prompt의 역할 중 하나는 특정 domain이나 context에 model이 input을 해석하도록 미리 준비시키는 것이 아닐까?
Conclusion
Prompt Tuning의 주요 성과
1)효율적인 다운스트림 태스크 적응
- Frozen pre-trained 모델을 유지하면서, prompt Tuning이 SuperGLUE 벤치마크에서 전통적인 모델 튜닝에 견주는 성능
- 특히, 모델 크기가 증가할수록 성능 good
2)Zero-shot domain transfer
- Prompt Tuning이 generalization을 개선하여, 새로운 도메인에서도 강력한 성능을 발휘
- 모델의 general-purpose language understanding 매개변수를 고정하고, 다운스트림 학습을 lightweight parameter로 제한함으로써 특정 도메인의 overfitting 방지
추가적인 장점
1)storage & serving cost 절감
- Frozen pre-trained 모델을 활용하면, 다중 태스크에 효율적으로 대응할 수 있는 multi-task serving이 가능
- 고성능 prompt ensembling도 효율적으로 수행 가능
2)태스크 정의와 언어 모델링의 분리
- task-defining parameters을 일반 언어 모델링 매개변수와 분리하는 접근
우히히 첫 논문읽기~ Abstract에서만 두 시간이 걸린 걸 보니 '맞다 뭐든 처음은 늘 버벅되고 어려웠었지!'를 새삼 깨닫는다!ㅎㅎ 나중에는 논문 척척 읽어낼 내 모습이 기대가 되면서도~ 나름 공부를 열심히 한 machine learning 과목이었는데 막상 논문을 접하니 내가 배운 건 정말 극극극극극히 기본적인 내용이었구나,,^^;; 어찌됐든 처음읽고 공부해본 논문! 특별하니까 블로그에 남겨둘테다