
dew's CSE Studying
12 정렬 (C언어로 쉽게 풀어쓴 자료구조) 본문
12.1 정렬이란?
정렬(sorting): 물건을 크기순으로 오름차순(ascending order)이나 내림차순(descending order)으로 나열하는 것
구조
레코드(record): 정렬시켜야 될 대상
필드(field): 레코드의 나누어진 단위(ex. 이름, 학번, 주소, 전화번호)
키(key): 레코드와 레코드를 식별해주는 역할을 하는 필드(ex. 학번 필드->학생을 구별해줌)
"정렬이란 결국 레코드들을 키값의 순서로 재배열하는 것!"

정렬 알고리즘
- 단순하지만 비효율적인 방법 - 삽입 정렬, 선택 정렬, 버블 정렬 등
- 복잡하지만 효율적인 방법 - 퀵 정렬, 히프 정렬, 합병 정렬, 기수 정렬 등
-자료의 개수가 일정 개수를 넘어가면 반드시 효율적인 알고리즘을 사용해야 한다
- 내부 정렬(internal sorting) - 정렬하기 전에 모든 데이터가 메인 메모리에 올라와 있는 정렬
- 외부 정렬(external sorting) - 외부 기억 장치에 대부분의 데이터가 있고 일부만 메모리에 올려놓은 상태에서 정렬을 하는 방법
- 안정성(stability)O - 입력 데이터에 동일한 키 값을 갖는 레코드가 여러 개 존재할 경우, 이들 레코드의 상대적인 위치가 정렬 후에도 바뀌지 않음 (삽입 정렬, 버블 정렬, 합병 정렬)
- 안정성(stability)X - 같은 키값을 갖는 레코드들이 정렬 후에 위치가 바뀌는 경우
12.2 선택 정렬
선택 정렬의 원리
오른쪽 리스트에서 가장 작은 숫자를 선택하여 왼쪽 리스트로 이동하는 작업을 오른쪽 리스트가 공백 상태가 될 때까지 되풀이한다

-제자리 정렬(in-place sorting): 입력 배열 이외에는 다른 추가 메모리를 요구하지 않는 정렬 방법
- 입력 배열에서 최소값을 발견
- 이 최소값을 배열의 첫번째 요소와 교환한다
- 첫번째 요소를 제외한 나머지 요소들 중에서 가장 작은 값을 선택하고 이를 두번째 요소와 교환한다
- 이 절차를 (숫자개수-1)만큼 되풀이한다

선택 정렬의 알고리즘
#define SWAP(x, y, t) ( (t)=(x), (x)=(y), (y)=(t))
void selection_sort(int list[], int n)
{
int i, j, least, temp;
for (i=0; i < n-1; i++) {
least = i;
for (j=i+1; j<n; j++) // 최소값 탐색
if(list[j] < list[least]) least = j;
SWAP(list[i], list[least], temp);
}
}
선택 정렬의 분석
비교횟수: O(n^2)(외부루프 n-1번, 내부루프 (n-1)-i번)
이동횟수: 3(n-1) (레코드 교환횟수=외부루프의 실행횟수, 한 번 교환하기 위해 3번의 이동 필요)
전체 시간 복잡도: O(n^2)
-안정성을 만족하지 않음(특히 같은 레코드가 있는 경우)

12.3 삽입 정렬
삽입 정렬의 원리
삽입 정렬(insert sort): 정렬되어 있는 리스트에 새로운 레코드를 적절한 위치에 삽입하는 과정을 반복한다
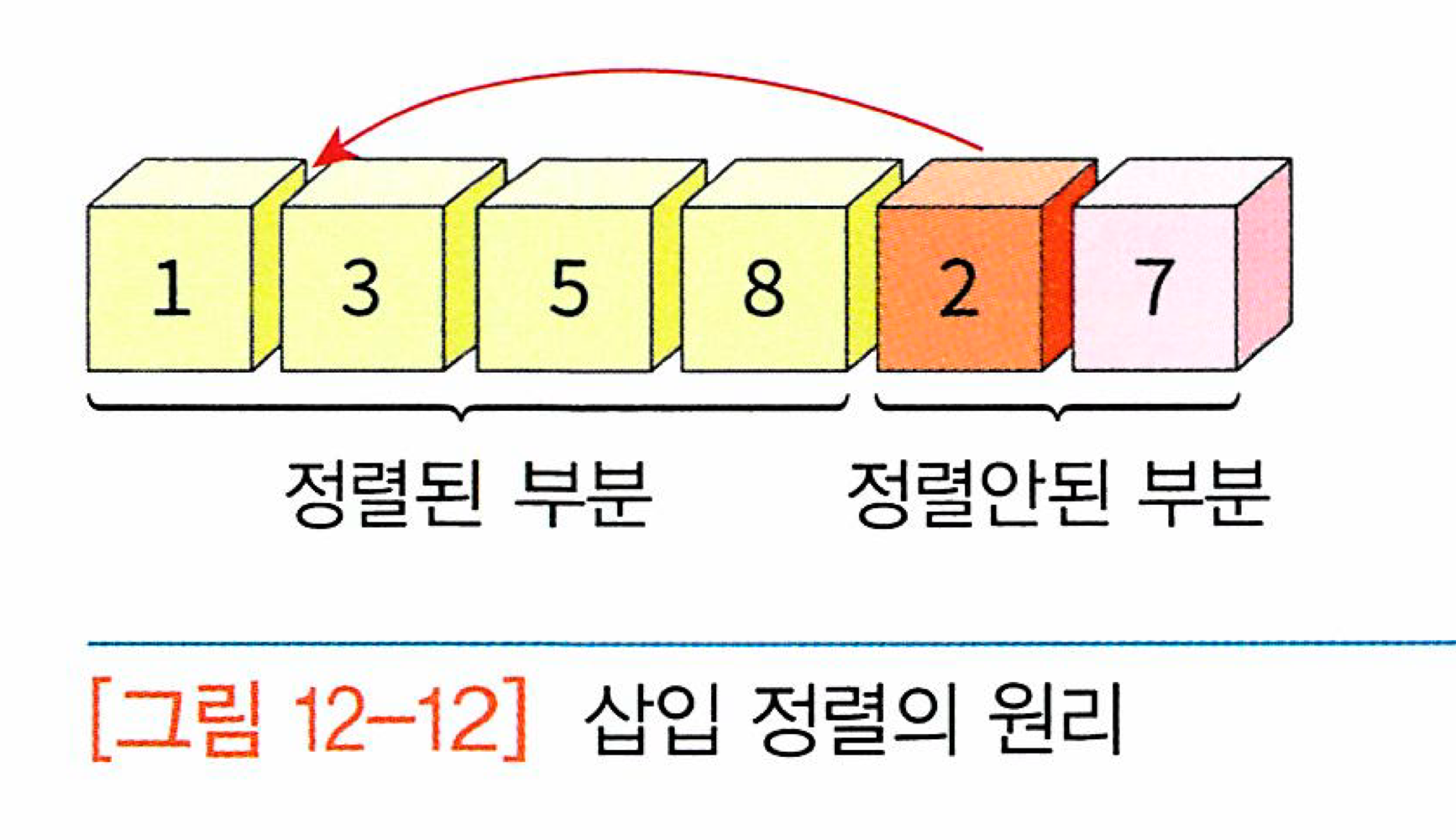
선택 정렬과 마찬가지로 입력 배열을 정렬된 부분/정렬되지 않은 부분으로 나누어 사용한다
방법: 정렬X부분의 첫 번째 숫자가 정렬O부분의 어느 위치에 삽입되어야 하는가?를 판단 후 숫자를 삽입한다
결과: 정렬된 부분의 크기 +1 / 정렬X 부분의 크기 -1

삽입 정렬의 알고리즘

- 인덱스 1부터 시작한다. 인덱스 0은 이미 정렬된 것으로 볼 수 있다
- 현재 삽입될 숫자인 i번째 정수를 key 변수로 복사
- 현재 정렬된 배열은 i-1까지이므로 i-1번째부터 역순으로 조사한다
- j값이 음수가 아니고 key값보다 정렬된 배열에 있는 값이 크면
- j번째를 j+1번째로 이동한다
- j를 하나 감소한다
- j번째 정수가 key보다 작으므로 j+1번째가 key값이 들어갈 위치이다

삽입 정렬의 c언어 구현
// 삽입 정렬
void insertion_sort(int list[], int n)
{
int i, j, key;
for (i=1; i<n; i++) {
key = list[i];
for (j=1; j>=0 && list[j]>key; j--)
list[j+1]=list[j]; /* 레코드의 오른쪽 이동 */
list[j+1] = key;
}
}
삽입 정렬의 복잡도 분석
입력자료가 이미 정렬되어 있는 경우: O(n) (외부루프 n-1, 총비교횟수 n-1, 총이동횟수 2(n-1))
입력자료가 역순인 경우
-총 비교횟수(외부루프 안 각 반복마다 i번의 비교)

-총 이동횟수(외부루프 각 단계마다 i+2번의 이동)

=>삽입정렬은 레코드 양이 많고 레코드 크기가 클 경우 적합하지 않다
-안정한 정렬 방법
-레코드 수가 적을 경우 알고리즘 자체가 매우 간단하므로 유리하다
-대부분의 레코드가 이미 정렬되어 있는 경우 매우 효율적

12.4 버블 정렬
버블 정렬의 원리
버블정렬(bubble sort): 인접한 2개의 레코드를 비교하여 크기가 순서대로 되어있지 않으면 서로 교환하는 비교-교환 과정을 리스트의 왼쪽 끝에서 오른쪽 끝까지 진행한다
-한 번의 비교-교환 과정(스캔)이 완료되면 가장 큰 레코드가 리스트의 오른쪽 끝으로 이동된다
-전체 숫자가 전부 정렬될 때까지 계속된다


버블 정렬의 알고리즘

버블 정렬의 c언어 구현
// 버블 정렬
void bubble_sort(int list[], int n)
{
int i, j, temp;
for(i=n-1; i>0; i--) {
for (j=0; j<i; j++) {
/* 앞 뒤의 레코드를 비교한 후 교체 */
if (list[j] > list[j+1])
SWAP(list[j], list[j+1], temp);
}
}
}
버블 정렬의 복잡도 분석
-비교횟수: 최선, 평균, 최악의 경우 모두 동일하다

-이동횟수
- 최악: 입력자료가 역순으로 정렬되어 있는 경우 = 비교연산횟수x3 (SWAP함수가 3개의 이동을 포함하고 있기 때문)
- 최선: 입력자료가 이미 정렬되어 있는 경우 = 0
- 평균: 자료이동이 0번~i번 같은 확률로 발생
-총 알고리즘: O(n^2)
-문제점: 순서에 맞지 않은 요소를 인접한 요소와 교환한다
-레코드의 이동과다: swap 작업이 move 작업보다 더 복잡하기 때문에 잘 쓰이지 않는다

12.5 쉘 정렬
쉘 정렬의 원리
쉘 정렬(shell sort): 삽입정렬이 어느정도 정렬된 리스트에서 대단히 빠른 것에서 착안
-삽입 정렬의 O(n^2)보다 빠르다
-삽입 정렬의 최대 문제점: 요소들이 삽입될 때 이웃한 위치로만 이동한다(if 삽입되어야할 위치가 현재 위치에서 멀리 떨어진 곳이라면 이동량↑↑)
| 삽입정렬 | 쉘정렬 |
| O(n^2) | 더 빠르다 |
| 삽입시 이웃한 위치로만 이동 | 요소들이 멀리 떨어진 위치로도 이동 가능 |
| 전체의 리스트를 한 번에 정렬하지 않는다 |
쉘정렬의 정렬 알고리즘
- 먼저 정렬해야할 리스트를 일정한 기준에 따라 분류
- 연속적이지 않은 여러 개의 부분리스트를 만든다(이때 주어진 리스트의 각 k번째 요소를 추출)
- 각 부분 리스트를 삽입 정렬을 이용하여 정렬한다
- 모든 부분 리스트가 정렬되면 다시 전체 리스트를 더 적은 개수의 부분리스트로 만든다
- 부분 리스트의 개수가 1이 될 때까지 되풀이한다(각 스텝마다 간격 k를 줄여가므로 수행과정이 반복될 때마다 하나의 부분 리스트에 속하는 레코드들의 개수는 증가한다)

쉘 정렬의 구현
// gap만큼 떨어진 요소들을 삽입 정렬
// 정렬의 범위는 first에서 last
inc_insertion_sort(int list[], int first, int last, int gap)
{
int i, j, key;
for(i=first+gap; i<=last; i=i+gap) {
key = list[i];
for (j=i-gap; j>=first && key<list[j]; j=j-gap)
list[j+gap] = list[j];
list[j+gap]=key;
}
}
void shell_sort(int list[], int n) //n=size
{
int i, gap;
for (gap=n/2; gap>0; gap=gap/2) {
if ((gap % 2)==0) gap++;
for (i=0; i<gap; i++) // 부분 리스트의 개수는 gap
inc_insertion_sort(list, i, n-1, gap);
}
}
쉘 정렬의 분석
장점:
- 연속적이지 않은 부분리스트에서 자료의 교환이 일어나면 더 큰 거리를 이동한다(삽입정렬: 한 번에 한 씩만 이동됨)
따라서 교환되는 아이템들이 삽입정렬보다는 최종 위치에 더 가까이 있을 가능성↑ - 부분리스트가 점진적으로 정렬된 상태가 되므로 삽입정렬 속도 증가
시간적 복잡도
- 최악 O(n^2)
- 평균 O(n^1.5)

12.6 합병 정렬
-입력데이터가 많을 때 훨씬 빠른 방법들을 알아보자~
합병 정렬의 개념
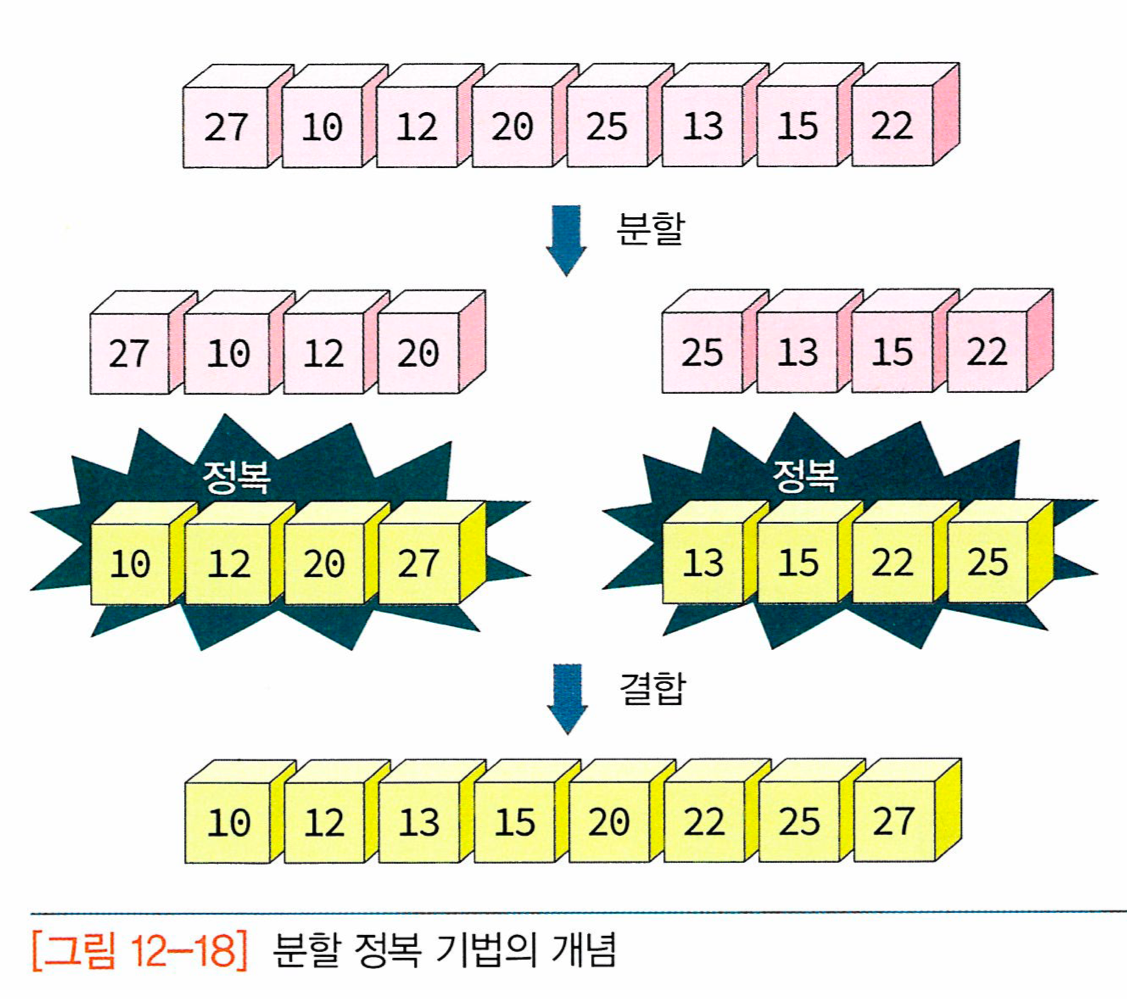
합병 정렬(merge sort): 하나의 리스트를 두 개의 균등한 크기로 분할하고 -> 분할된 부분 리스트를 정렬한 다음 -> 두 개의 정렬된 부분 리스트를 합하여 전체가 정렬된 리스트를 얻고자 하는 것
-분할 정복 기법에 바탕을 두고 있다
- 분할 정복 기법(divide and conquer): 문제를 작은 2개의 문제로 분리하고 각각을 해결->결과를 모아서 원래의 문제를 해결
- 분리된 문제가 아직도 해결하기 어렵다면(=충분히 작지 않다면) 분할 정복 방법을 연속하여 다시 적용
- 대개 순환호출을 이용하여 구현
-합병 정렬의 단계들
- 분할(divide): 입력 배열을 같은 크기의 2개의 부분 배열로 분할한다
- 정복(conquer): 부분 배열을 정렬한다. 부분 배열의 크기가 충분히 작지 않으면 순환 호출을 이용하여 다시 분할 정복 기법을 적용
- 결합(combine): 정렬된 부분 배열들을 하나의 배열에 통합한다

합병 정렬 알고리즘

- 만약 나누어진 구간의 크기가 1 이상이면
- 중간 위치를 계산한다
- 앞쪽 부분 배열을 정렬하기 위하여 merge_sort 함수를 순환 호출한다
- 뒤쪽 부분 배열을 정렬하기 위하여 merge_sort 함수를 순환 호출한다
- 정렬된 2개의 부분 배열을 통합하여 하나의 정렬된 배열로 만든다
-실제로 정렬이 이루어지는 시점: 2개의 리스트를 합병(merge)하는 단계


-하나의 배열 안에 두 개의 정렬된 부분리스트가 저장되어있다
합병 정렬의 C언어 구현
int sorted[MAX_SIZE]; //추가 공간이 필요
/* i는 정렬된 왼쪽 리스트에 대한 인덱스
j는 정렬된 오른쪽 리스트에 대한 인덱스
k는 정렬될 리스트에 대한 인덱스 */
void merge(int list[], int left, int mid, int right)
{
int i,j,k,l;
i=left; j=mid+1; k=left;
// 분할 정렬된 list의 합병
while (i <= mid && j <= right) {
if (list[i] <= list[j])
sorted[k++] = list[i++];
else
sorted[k++] = list[j++];
}
if (i>mid) // 남아 있는 레코드의 일괄 복사
for (l=j; l<=right; l++)
sorted[k++] = list[l];
else // 남아 있는 레코드의 일괄 복사
for (l=i; l<=mid; l++)
sorted[k++] = list[l];
// 배열 sorted[]의 리스트를 배열 list[]로 재복사
for (l=left; l<=right; l++)
list[l]=sorted[l];
}
void merge_sort(int list[], int left, int right)
{
int mid;
if (left<right) {
mid = (left+right) / 2; //리스트의 균등 분할
merge_sort(list, left, mid); //부분 리스트 정렬
merge_sort(list, mid+1, right); //부분 리스트 정렬
merge(list, left, mid, right); //합병
}
}
합병 정렬의 복잡도 분석
비교횟수
- 크기 n인 리스트를 정확히 균등 분배하므로 log(n)개의 패스
- 각 패스에서 리스트의 모든 레코드 n개를 비교하므로 n번의 비교연산
이동횟수
- 레코드의 이동이 각 패스에서 2n번 발생하므로 전체 레코드의 이동은 2n*log_(n)번 발생
단점
- 임시 배열이 필요
- 레코드의 크기가 큰 경우에는 매우 큰 시간적 낭비 초래(레코드를 연결 리스트로 구성하여 합병 정렬할 경우, 매우 효율적)
-최적, 평균, 최악의 경우 큰 차이 없이 O(n*log_2(n))의 복잡도
(이유:데이터 분포에 영향을 덜 받기 때문에 입력데이터가 무엇이든 간에 정렬되는 시간이 동일)
-안정적이며 데이터의 초기 분산 순서에 영향을 받음

12.7 퀵 정렬
퀵 정렬의 개념
퀵 정렬(quick sort):
-매우 빠른 수행 속도를 자랑하는 정렬 방법
-분할-정복법에 근거
-전체리스트->2개의 부분 리스트->각 부분리스트를 다시 퀵정렬
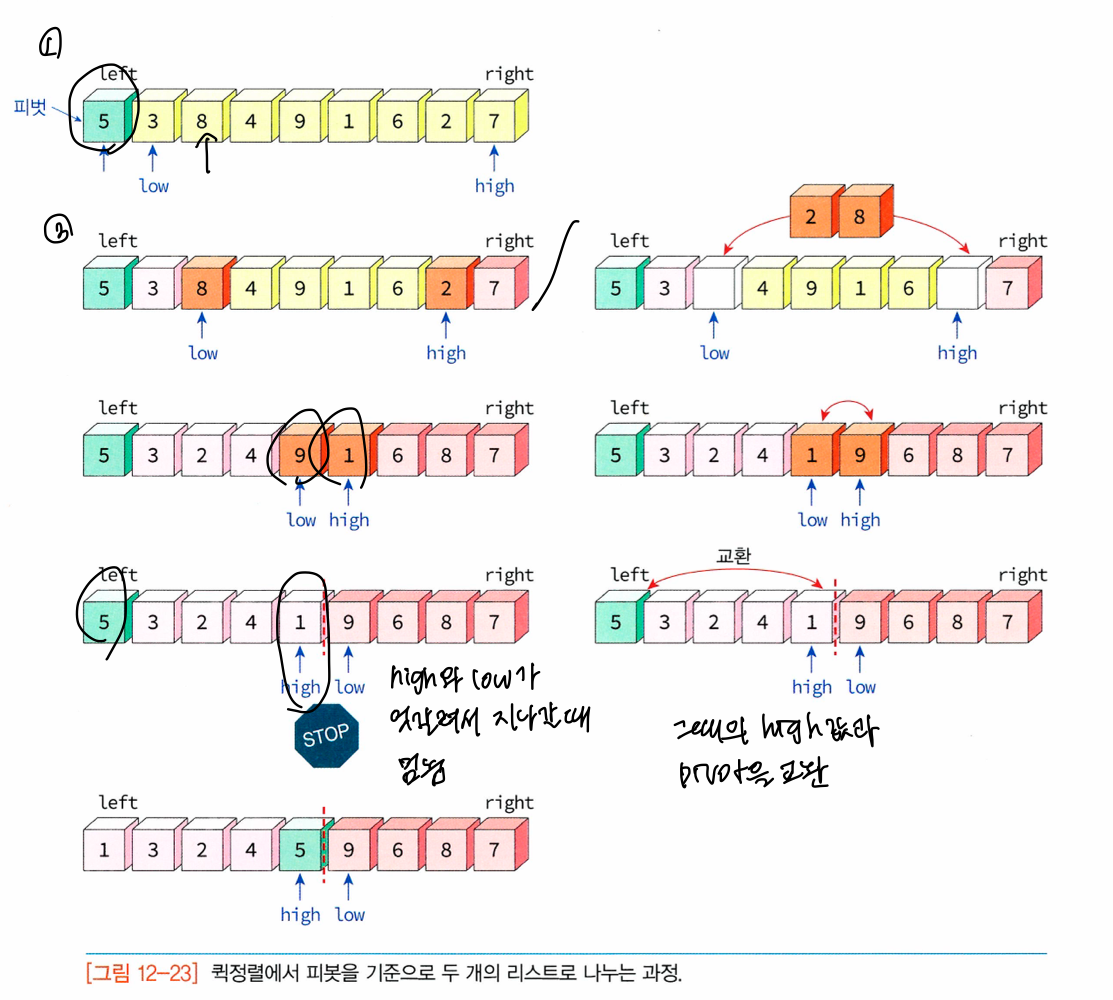
- 리스트 안에서 요소 한 개를 피벗(pivot)으로 지정
- 피벗보다 작으면 왼쪽으로, 크면 오른쪽으로
- 이 상태에서 피벗을 제외한 왼쪽/오른쪽 리스트를 다시 정렬

-퀵 정렬 함수가 다시 부분 리스트에 대하여 순환호출된다
-부분리스트에서도 다시 피벗을 정하고 피벗을 기준으로 2개의 부분리스트로 나누는 과정이 되풀이된다
-부분리스트들이 더이상 분할이 불가능할 때까지 나누어진다
퀵 정렬 알고리즘
void quick_sort(int list[], int left, int right)
{
if(left<right) {
int q=partition(list, left, right);
quick_sort(list, left, q-1);
quick_sort(list, q+1, right);
}
}- 정렬할 범위가 2개 이상의 데이터면
- partition 함수를 호출하여 피벗을 기준으로 2개의 리스트로 분할한다. partition 함수의 반환값은 피봇의 위치가 된다
- left에서 피벗 위치 바로 앞까지를 대상으로 순환호출한다(피벗은 제외된다)
- 피벗 위치 바로 다음부터 right까지를 대상으로 순환호출한다(피벗은 제외된다)
-partition 함수: 배열 list의 left부터 right까지의 리스트를 피벗을 기준으로 2개의 부분리스트로 나누는 역할
int partition(int list[], int left, int right)
{
int pivot, temp;
int low, high;
low=left;
high=right+1;
pivot=list[left];
do {
do
low++;
while (list[low] < pivot);
do
high--;
while (list[high] > pivot);
if (low<high) SWAP(list[low], list[high], temp);
} while (low<high);
SWAP(list[left], list[high], temp);
return high;
}

퀵 정렬의 복잡도 분석
-최선의 경우(거의 균등한 리스트로 분할되는 경우)
- 총 비교횟수: O(nlog_2(n))
- 총 이동횟수: 비교횟수보다 적으므로 무시 가능
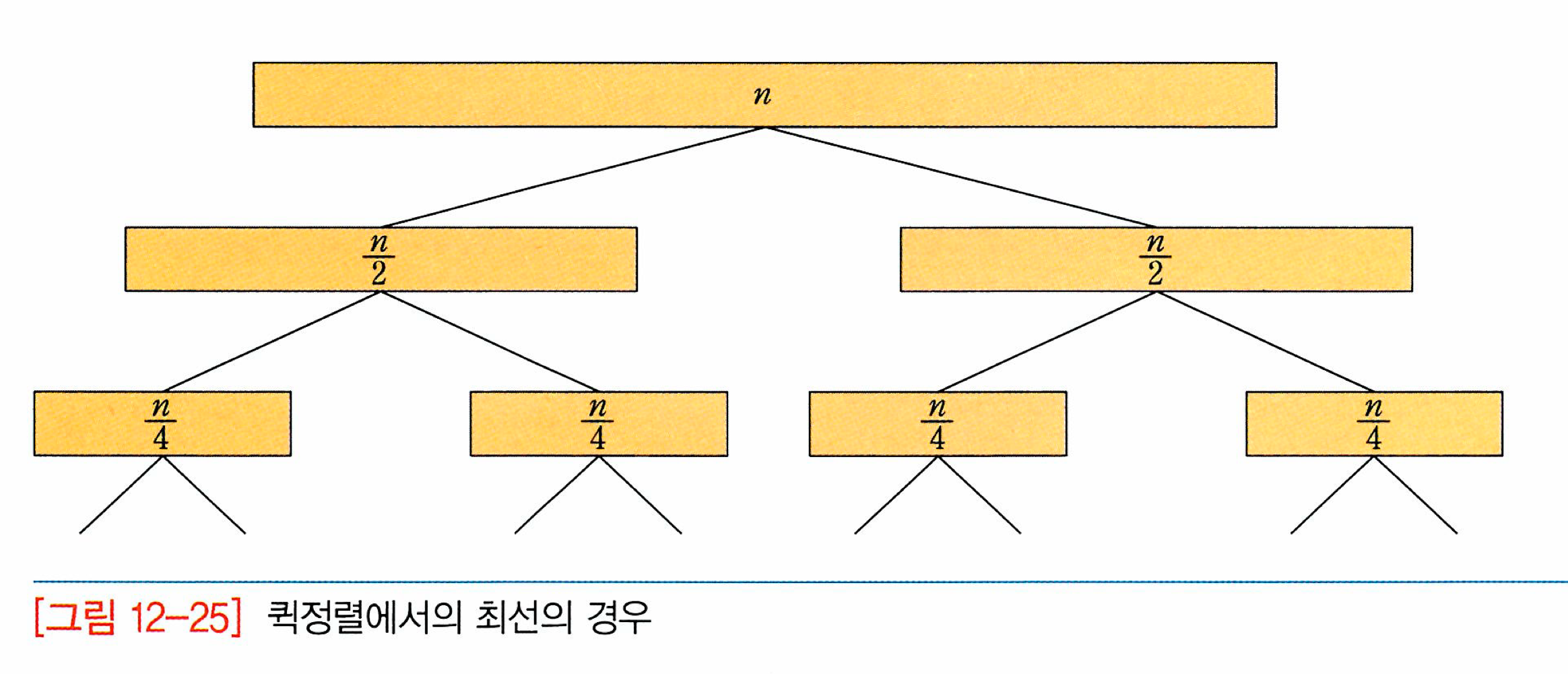
-최악의 경우(극도로 불균등한 리스트로 분할되는 경우)
- 총 비교횟수: O(n^2)
- 총 이동횟수: 비교횟수보다 적으므로 무시 가능

퀵 정렬의 장단점
-장점: 속도가 빠르고, 추가 메모리 공간을 필요로 하지 않는다
-단점: 정렬된 리스트에 대해서는 오히려 수행시간이 더 많이 걸린다
-해결:중간값(medium)을 피벗으로 선택하면 불균등 불할 완화 가능
-medium of three: 리스트의 왼,오,중간의 3개의 데이터 중 중간값을 선택하는 방법
퀵 정렬 라이브러리 함수의 사용

12.8 히프 정렬
히프 정렬의 개념
히프: 우선순위 큐를 완전 이진 트리로 구현하는 방법
-최댓값&최솟값 추출이 쉽다
-종류: 최대히프/최소히프(<-얘를 정렬에서 사용)(부모 노드 값<자식 노드 값)
히프정렬(heap sort): 정렬할 배열을 먼저 최소 히프로 변환->가장 작은 원소부터 차례대로 추출하는 정렬 방법
12.9 기수 정렬
기수 정렬의 원리
기수 정렬(radix sort): 입력 데이터에 대해서 어떤 비교 연산도 실행하지 않고 데이터를 정렬할 수 있는 색다른 정렬 기법
-유일하게 정렬에 기초한 방법들 중 O(nlog2(n))라는 이론적 하한선을 깰 수 있는 방법
-기수 정렬의 시간복잡도: O(kn) (k<4)
-문제: 기수 정렬은 추가적인 메모리를 필요로 한다(근데 그래도 다른 것보다 빠름)
-단점: 정렬할 수 있는 레코드의 타입이 한정된다(동일한 길이의 숫자/문자열로 구성되어야 한다)
한 자리 수의 정렬
ex) (8,2,7,3,5)
- 10개의 버킷을 만들어 입력 데이터를 각 자리수의 값에 따라 상자에 넣는다
- 순차적으로 버킷 안에 들어 있는 숫자를 읽는다

두 자리 수의 정렬
ex) (28, 93, 39, 81, 62, 72, 38, 26)
->이 경우 일의 자리 수를 먼저 사용->십의 자리 수를 사용

기수 정렬의 알고리즘
-LSD(Least Significant Digit): 가장 낮은 자리수
-MSD(Most Significant Digit): 가장 높은 자리수

-먼저 들어간 애들이 먼저 나와야 하므로 각각의 버킷은 큐로 구현
-버킷의 개수는 키의 표현 방법과 밀접한 관계
- 이진법: 버킷2개
- 알파벳 문자: 버킷 26개
- 십진법: 버킷 10개
기수 정렬의 구현
기수 정렬의 분석
O(n)
-장점: 다른 정렬 방법에 비해 비교적 빠른 수행시간
-문제점: 정렬에 사용되는 키값이 숫자로 표현되어야만 적용 가능
12.10 정렬 알고리즘의 비교

-정렬해야할 레코드의 수, 크기, 타입에 따라 달라지므로 적합한 정렬방법 사용해야 함
12.11 정렬의 응용: 영어 사전을 위한 정렬
'3-1 > 자료구조 again' 카테고리의 다른 글
| 14 해싱 (C언어로 쉽게 풀어쓴 자료구조) (0) | 2024.12.05 |
|---|---|
| 13 탐색 (C언어로 쉽게 풀어쓴 자료구조) (0) | 2024.12.03 |
| 11 그래프2 (C언어로 쉽게 풀어쓴 자료구조) (2) | 2024.11.15 |
| 10 그래프1 (C언어로 쉽게 풀어쓴 자료구조) (4) | 2024.11.08 |
| 09 우선순위 큐 (C언어로 쉽게 풀어쓴 자료구조) (2) | 2024.10.23 |



